Cara Mengatasi Data Tidak Berdistribusi Normal dengan SPSS
Cara Mengatasi Data Tidak Normal dengan SPSS
Dalam analisis statistik, asumsi normalitas data sangat penting, terutama dalam uji parametrik seperti regresi linier, ANOVA, dan uji-t. Jika data yang digunakan tidak berdistribusi normal, maka hasil analisis bisa menjadi tidak valid. Oleh karena itu, perlu dilakukan langkah-langkah untuk mengatasi data yang tidak normal. Sebelum mengatasi data tidak normal, Kita harus tau hal-hal yang menyebabkan data tidak berdistribusi normal.
Berikut ini beberapa penyebab data bisa berdistribusi tidak normal:
1. Ukuran Sampel Kecil
Ketika ukuran sampel terlalu kecil (misalnya kurang dari 30), distribusi data sering kali tidak mengikuti distribusi normal. Semakin besar sampel, semakin mendekati distribusi normal sesuai dengan Teorema Limit Central.
2. Adanya Outlier (Pencilan)
Outlier adalah nilai ekstrem yang sangat berbeda dari data lainnya. Nilai ini bisa menyebabkan distribusi menjadi miring (skewed) atau memiliki kurtosis yang tinggi, sehingga data menjadi tidak normal.
3. Data Tidak Homogen
Jika data berasal dari beberapa kelompok yang memiliki karakteristik berbeda, distribusinya bisa menjadi tidak normal.
4. Skala Pengukuran yang Tidak Tepat
Jika data berbentuk ordinal tetapi dianalisis seolah-olah interval atau rasio, distribusi data bisa menjadi tidak normal.
5. Kesalahan Pengambilan Data
Jika data diperoleh dari instrumen yang kurang akurat atau ada kesalahan saat pengumpulan, hasilnya bisa bias dan menyebabkan distribusi tidak normal.
Ada berapa cara dalam mengatasi data tidak berdistribusi normal diantaranya yaitu:
1. Menghilangkan data outlier
2. Menggunakan transformasi data
3. Menggunakan uji statistik nonparametrik
Pada artikel kali ini, untuk mengatasi data tidak berdistribusi normal dengan cara menghilangkan data outlier.
Contoh kasus data berdistribusi tidak normal
Suatu rumah sakit melakukan percobaan treatment diet khusus kepada para pasien yang menderita tekanan darah tinggi. Sebelum dilakukan secara masal, dilakukan tes percobaan dengan treatment diet khusus selama 3 bulan terhadap beberapa pasien. Sampel di ambil secara random. Sebelum treatment, dilakukan pengukuran tekanan darah, kemudian akan diukur kembali setelah treatment.
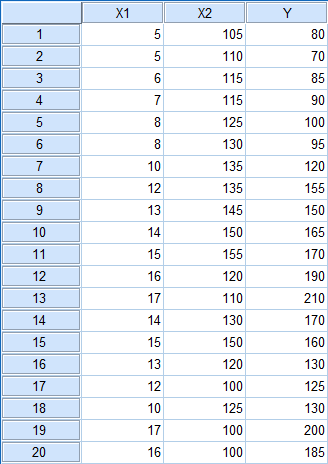
Berikut ini data pengukuran tekanan darah sebelum dan sesudah treatment
 |
| Data Tekanan Darah |
Langkah pertama yaitu dengan mengecek apakah data normal atau tidak yaitu dengan menggunakan uji normalitas. Berikut ini langkah-langkah uji normalitas dengan software SPSS:
1. Buka software SPSS, kemudian masukkan data seperti gambar di bawah ini.
| Tampilan variabel view SPSS |
 |
| Tampilan data view SPSS |
2. Setelah data sudah di input ke SPSS, langkah selanjutnya yaitu klik Analyze, pilih Descriptive Statistics, lalu pilih Explore, maka akan muncul kotak dialog explore.
 |
3. Masukkan kedua variabel tersebut kedalam kolom Dependent List.

4. Pilih Plots, maka akan muncul kotak dialog Explore: Plots. Selanjutnya centang normality plots with tests.

5. Kemudian klik Continue
6. Lalu klik OK, maka SPSS akan memunculkan output sebagai berikut.

Membaca Hasil Uji Normalitas SPSS
Output yang digunakan untuk melakukan uji Normalitas yaitu pada tabel Tests of Normality.
Pada contoh kasus ini karena jumlah sampel berukuran 12, maka menggunakan uji normalitas Shapiro-Wilk (pada beberapa literatur jika jumlah sampel kurang dari 30,maka menggunakan shapiro-wilk)
Dapat dilihat pada tabel test of normality diperoleh nilai Sig. Variabel TD_Sebelum treatment 0.025 dan variabel TD_Sesudah treatment 0.021 < α (0.05) maka kedua variabel tersebut berdistribusi tidak normal. Perlu diingat kembali pedoman pengambilan keputusan uji normalitas, jika nilai sig > α (0.05) maka data berdistribusi normal dan sebaliknya jika nilai sig < α (0.05) maka data tidak berdistribusi normal.
 |
| Boxplot variabel Tekanan Darah sebelum Treatment |
 |
| Boxplot variabel Tekanan Darah setelah Treatment |
Pada output boxplot 1 (variabel Tekanan Darah sebelum Treatment) dan 2 (variabel Tekanan Darah setelah Treatment), dapat kita simpulkan bahwa ada 2 data yang outlier atau data yang sangat menyimpang, yaitu data no 5 dan no 12. oleh karena itu kedua data tersebut harus kita buang/hapus agar data berdistribusi normal.
Cara menghapus Data/sampel
Untuk menghapus kedua data tersebut caranya sangat mudah, caranya yaitu klik nomer data 5 sampai berwarna kuning, setelah itu klik menu edit terus klik clear. cara yang sama untuk data nomer 12.
 |
| Data Outlier sebelum dihapus |
 |
| Data Outlier setelah dihapus |
Setelah data tersebut dihapus, kita uji lagi untuk mengetahui apakah data sudah berdistribusi normal atau tidak. Caranya sama seperti yang diatas yaitu:
1. Klik Analyze, pilih Descriptive Statistics, lalu pilih Explore, maka akan muncul kotak dialog explore.
2. Masukkan kedua variabel tersebut kedalam kolom Dependent List.

3. Pilih Plots, lalu centang normality plots with tests.

4. Kemudian klik Continue
5. Lalu klik OK, maka SPSS akan memunculkan output sebagai berikut.
 |
| Output uji normalitas |
Kita langsung fokus ke tabel Tests of Normality untuk melihat hasil uji normalitas. Pada tabel test of normality diperoleh nilai Sig. Variabel TK_Sebelum treatment 0.878 dan variabel TK_Sesudah treatment 0.460, karena kedua variabel tersebut > α (0.05) maka kedua variabel tersebut berdistribusi normal.
 |
| Boxplot variabel Tekanan Darah sebelum Treatment |
 |
| Boxplot variabel Tekanan Darah setelah Treatment |
Kita juga dapat melihat pada grafik boxplot kedua variabel tersebut. Pada grafik boxplot tersebut dapat kita lihat bahwa sudah tidak ada data/sampel yang outlier. Setelah data sudah berdistribusi normal kita bisa lanjut menggunakan uji statistik parametrik. Pada kasus ini lanjut menggunakan uji paired sampel t test.
Demikian artikel terkait Cara Mengatasi Data Tidak Normal dengan membuang data outlier pada software SPSS, semoga artikel ini bermanfaat, terimakasih.
.png)


Komentar
Posting Komentar